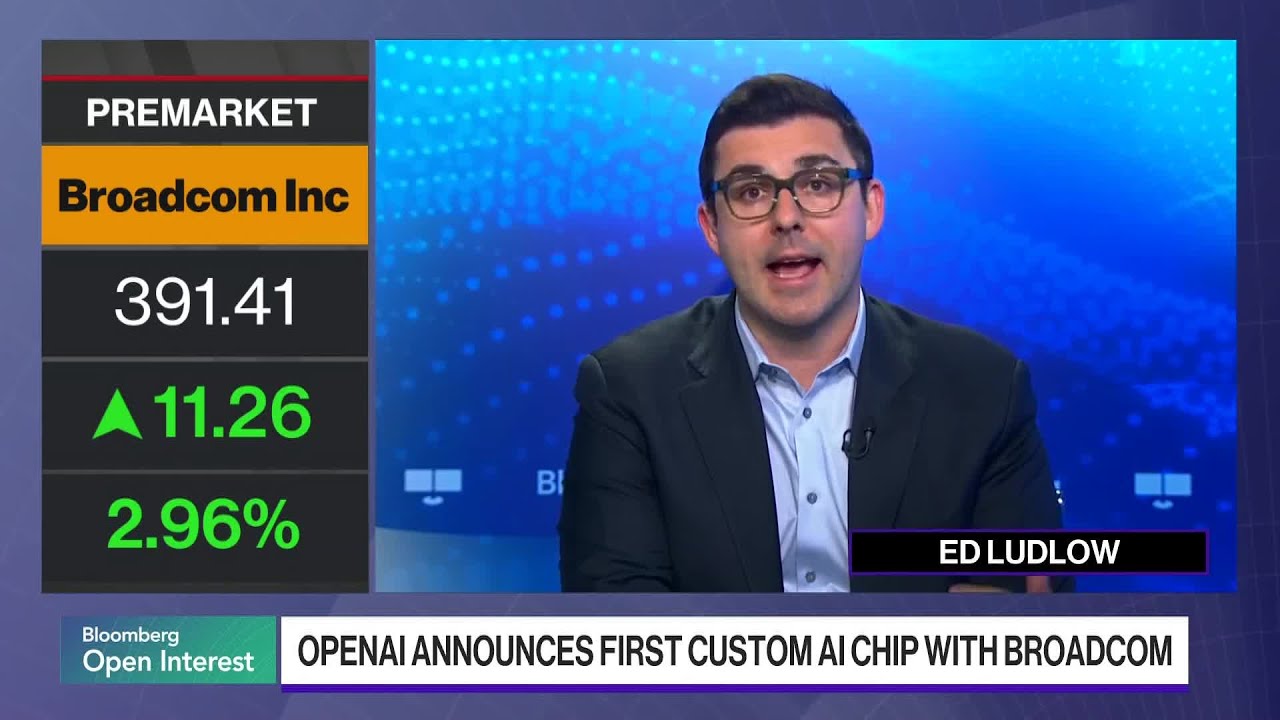
SAN FRANCISCO – Every query on ChatGPT costs OpenAI money on Nvidia’s terms. For years, that was simply the tax on being the company that had to serve one of the world’s most computationally expensive products with hardware it did not design and could not price. On Tuesday, OpenAI said it has been building an exit.
Jalapeño, the company’s first custom AI chip, developed with Broadcom and manufactured on TSMC’s 3nm process, was officially revealed on June 24 in an announcement that doubles as a statement about where OpenAI thinks the infrastructure industry is heading. The chip is designed exclusively for inference: running models rather than training them, the workload that grows with every new ChatGPT user and every new API call, and the one where OpenAI’s compute bill is largest.
The reveal was staged as a physical handoff. Broadcom CEO Hock Tan and semiconductor president Charlie Kawwas walked into OpenAI’s offices and placed a 300mm silicon wafer, holding roughly 50 to 60 Jalapeño ASICs, in the hands of Sam Altman and Greg Brockman. On the wafer’s surface, engineers had inscribed a phrase: “May we scale smoothly, exponentially and uneventfully through AGI.” The ceremony reads as theater. The chip itself is not.
Jalapeño’s architectural premise is straightforward. Nvidia’s GPUs are general-purpose accelerators capable of handling training workloads that can run for weeks, inference workloads serving millions of users simultaneously, video rendering, and scientific simulation. That flexibility costs silicon area, power, and dollars. An inference-only chip can allocate every transistor to the operations that matter for serving model queries, and nothing else. The design uses a systolic array, a grid of processing elements that pass data from cell to cell in rhythmic lockstep, optimized for the dense matrix multiplications at the core of LLM inference, rather than Nvidia’s more general CUDA architecture. The die measures approximately 840mm², close to the maximum reticle size achievable on EUV lithography systems, surrounded by six high-bandwidth memory modules. Everything about it is sized to the specific bottleneck that limits how cheaply ChatGPT can answer a question.
The economics claim that follows: 50% lower inference cost per token compared to current Nvidia GPU configurations. If that figure holds at production scale, OpenAI’s unit cost for serving its products roughly halves when Jalapeño systems go live. The company has not disclosed what that means in dollar terms, or what fraction of its current compute spend Jalapeño will eventually replace. The 50% figure is a design target, not a measured production result.
What is measured: engineering samples of the chip are running GPT-5.3-Codex-Spark at production target frequency and power. That is a meaningful milestone. It means the chip has cleared functional validation and is performing as designed in OpenAI’s own testing environment. Volume production is targeted for 2027.
The development timeline is the detail that carries the most independent meaning. Jalapeño went from initial specification to tape-out in nine months. High-performance ASICs of this class, reticle-scale, HBM-integrated, with custom high-speed network interfaces, typically take two to three years from specification to tape-out. Broadcom and OpenAI attribute the compression to three factors: deep software-hardware co-development that let OpenAI’s engineers and Broadcom’s silicon team optimize simultaneously rather than in sequence; Broadcom’s prior experience with AI accelerators for Google and Meta, which reduced the learning curve; and the use of OpenAI’s own AI models to accelerate parts of the chip’s design and verification process. That last claim is either a genuine inflection point in how advanced silicon gets built or a marketing narrative OpenAI has not published the methodology to support. The distinction matters.
The infrastructure commitments are not ambiguous. OpenAI and Broadcom are targeting deployment at gigawatt scale from 2026, in data centers built alongside Microsoft. The two companies have committed to a 10-gigawatt capacity target through 2029, as TechCrunch reported. Celestica is handling board, rack, and system integration. The supply chain behind Jalapeño has already been assembled.
That supply chain runs directly through the memory bottleneck that has defined AI infrastructure economics for the past year. Micron confirmed it is already sampling HBM4 for the Jalapeño platform, a detail that connects the chip announcement to the AI memory supply crunch that has constrained GPU performance and inflated hardware costs across the industry. Whether Micron can deliver that memory in the volumes OpenAI needs by 2027 is a different question. Micron’s own CEO has described supply visibility as uncertain through the end of 2026.
The competitive implications for Nvidia are specific and bounded. Jalapeño is not a product OpenAI intends to sell. It will not appear in any cloud marketplace, and it will not compete with Nvidia’s H200 or its successors for training workloads, where general-purpose GPU architecture remains deeply entrenched. What it does is remove the fastest-growing segment of AI compute, inference at consumer scale, from Nvidia’s billing relationship with its most visible customer. VentureBeat noted this follows the pattern Google established with TPUs and Meta with MTIA accelerators: both companies built custom inference hardware and continued buying Nvidia training chips. OpenAI is following the same logic, later and at larger scale.
Brockman described the chip as part of a “long-term full-stack infrastructure strategy to make compute more abundant.” Hock Tan put it in deployment terms: enabling gigawatt-scale data centers with Microsoft “beginning in 2026.” What neither addressed is whether OpenAI’s data center position will match its compute ambitions. Jalapeño deploys into Microsoft Azure infrastructure, not OpenAI-owned facilities. Owning the silicon is one layer of independence. Owning the rack, the power, and the real estate is a different problem, one that a well-timed ASIC does not solve. In the AI infrastructure competition reshaping the industry, control of the full stack has become the defining structural ambition of every major AI lab. Jalapeño is OpenAI’s opening move in that game.
One thing the announcement did not address: TSMC’s 3nm capacity is heavily contested. Apple holds the largest share of advanced-node EUV output and is ramping A-series and M-series chips simultaneously. Nvidia’s next-generation training accelerators sit on the same advanced nodes. OpenAI has not disclosed where it sits in TSMC’s wafer allocation queue, what its committed wafer volumes are, or what the per-unit cost structure looks like at production scale. The 50% cost reduction is a projection. Whether it becomes a business result sometime in 2027 depends on questions OpenAI has not yet answered.